Prio-reasoning
Apply the “Prio-reasoning” in RAG. “Refine” in LangChain and “MultiStepQueryEngine” in Llama-Index.
What is Prio-reasoning
Simply put, in a system with multiple iterations, the context before each iteration includes the output of the previous iteration. This is very similar to the calculation process of recurrent neural networks (RNN) and the Fibonacci sequence.

Another good way to explain it is that RAG based on Prio-reasoning is like a chat with short memory snippets.
In the RAG applications based on large language models, I currently see two applications based on Prio-reasoning:
- Refining
- Multi-Step Query
Both LangChain and Llama-Index have their own ready-made tools to achieve this.
LangChain
Refine
During the retrieval process, information extraction for each chunk (index) is based on the information of the chunk itself and the previous extracted result of the chunk. This process will call the LLM several times.

Chain process
For each Chunk, asking continuous questions is key. The trick is to add the result of the previous Chunk query to each question about a single Chunk, moving forward in this sequence until all Chunks have been traversed.
In short: Prio-reasoning from previous chunk response
During the whole process, there will be
- origin query
- response of last chunk query
- current chunk

Here is a LangSmith output of one QA example:
https://smith.langchain.com/public/c82bfc9d-5962-4771-9dbe-c4c9acf7c993/r
Please note that the output of the previous Chunk will be included as part of the message list:

The AI output of the query will be part the message list in the consecutive query. Each query not only retrieves the current chunk but also includes the response of the previous query.
Llama-Index
The utilization of Llama-Index in Prio-Reasoning includes a method known as “step query”, which involves a process of decomposition.
We regularly update the query with the initial query and the LLM output from the previous reasoning. The results produced each time are “remembered” and passed on to the next questioning process as part of the reasoning. The entire process is an iterative accumulation.
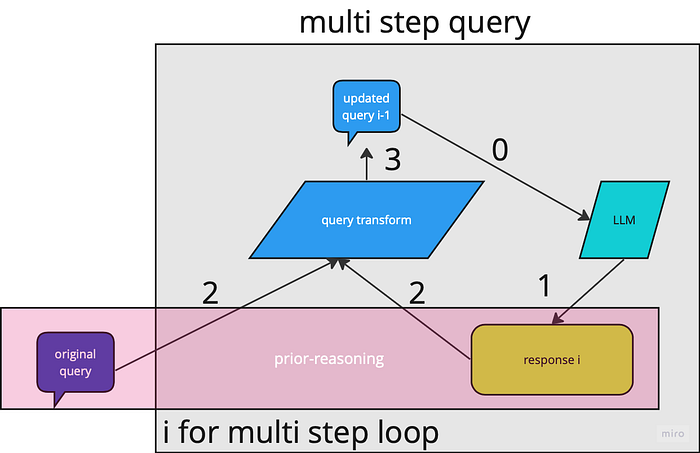
Process
Initially, the original query is used to generate the first LLM response. Subsequently, the query is transformed with the first response to create an updated query. This updated query is then queried again to produce a next response. The updated query and the new response are then subjected to another transformation, leading to the generation of a new updated query. This iterative process continues in this manner.
During the process the query on the LLM will be updated and exteneded.
In short: Prio-reasoning from updated query and response.
Here is one example on query the document , it is a paper about the topic Vector Search.
I have one initial question to the model, and there will follow three sub-queries to extend the init question.
Turned on the “verbose” flag we can see the intermediate output in terminal:


Code
I suggest to turn on the LangSmith to observe the LangChain refine.

Additional Reading(Optional)
Here’s some information on my explanation of the MultiStepQueryEngine source code as I learn:
The MultiStepQueryEngine in LlamaIndex is designed to handle complex queries that may require multiple steps to fully answer. It operates over an existing base query engine, along with the multi-step query transform. It processes queries in multiple steps, transforms the query at each step, synthesizes the final response from the results of the multi-step query processing, and uses a stop function to determine whether to stop the multi-step query processing early. Here is the relevant code:
class MultiStepQueryEngine(BaseQueryEngine):
def __init__(
self,
query_engine: BaseQueryEngine,
query_transform: StepDecomposeQueryTransform,
response_synthesizer: Optional[BaseSynthesizer] = None,
num_steps: Optional[int] = 3,
early_stopping: bool = True,
index_summary: str = "None",
stop_fn: Optional[Callable[[Dict], bool]] = None,
) -> None:
...The _query_multistep method is where the multi-step query processing happens, the BaseSynthesizer object synthesizes the final response from the results of the multi-step query processing by using the synthesize or asynthesize method. Here is the relevant code:
def _query_multistep(
self, query_bundle: QueryBundle
) -> Tuple[List[NodeWithScore], List[NodeWithScore], Dict[str, Any]]:
...
final_response = self._response_synthesizer.synthesize(
query=query_bundle,
nodes=nodes,
additional_source_nodes=source_nodes,
)
final_response = await self._response_synthesizer.asynthesize(
query=query_bundle,
nodes=nodes,
additional_source_nodes=source_nodes,
)The MultiStepQueryEngine is designed to handle complex queries that may require multiple steps to fully answer. It operates over an existing base query engine, along with the multi-step query transform. The final answer is indeed a combination of all sub-query answers. The context of each sub-query is handled by maintaining a prev_reasoning variable that accumulates the question and answer pairs from each step of the process. This variable is then used as part of the input to the _combine_queries method, which combines the original query with the previous reasoning to form the next sub-query.
def _query_multistep(
self, query_bundle: QueryBundle
) -> Tuple[List[NodeWithScore], List[NodeWithScore], Dict[str, Any]]:
....
......
while not should_stop:
if self._num_steps is not None and cur_steps >= self._num_steps:
should_stop = True
break
elif should_stop:
break
updated_query_bundle = self._combine_queries(query_bundle, prev_reasoning)
stop_dict = {"query_bundle": updated_query_bundle}
if self._stop_fn(stop_dict):
should_stop = True
break
cur_response = self._query_engine.query(updated_query_bundle)
cur_qa_text = (
f"\nQuestion: {updated_query_bundle.query_str}\n"
f"Answer: {cur_response!s}"
)
text_chunks.append(cur_qa_text)
for source_node in cur_response.source_nodes:
source_nodes.append(source_node)
final_response_metadata["sub_qa"].append(
(updated_query_bundle.query_str, cur_response)
)
prev_reasoning += (
f"- {updated_query_bundle.query_str}\n" f"- {cur_response!s}\n"
)
cur_steps += 1
nodes = [
NodeWithScore(node=TextNode(text=text_chunk)) for text_chunk in text_chunks
]
return nodes, source_nodes, final_response_metadata
# The _combine_queries method is used to combine or transform the current query
# with the previous reasoning. This method is used in the multi-step query process
# where the output of one query can influence the next query.
# The transformation is done by the _query_transform object, which is an instance of StepDecomposeQueryTransform.
def _combine_queries(
self, query_bundle: QueryBundle, prev_reasoning: str
) -> QueryBundle:
"""Combine queries."""
transform_metadata = {
"prev_reasoning": prev_reasoning,
"index_summary": self._index_summary,
}
return self._query_transform(query_bundle, metadata=transform_metadata)P.S
If you’re curious about how LangChain is used for Multi-Step Query, check out this video. One thing that is different in the implementation is that instead of accumulating Llama-Index, they generate some relevant sub-queries using LLM, then they answer them in sequence and finally, concat them, query and answer pairs, all together as context for the whole query bundle.
At some degree this is very like mulit-query pattern.
