LangGraph: hello,world!
Using the simplest “hello, world” example to explain LangGraph, once you understand this, you won’t be confused.
Reason
Many people DM me, complaining about the complexity of LangGraph. Actually, I think the tool itself is good, the problem lies in the official examples and the complexity of getting started. So I’ll just explain it using a simple “hello, world”, this way, any programmer can understand.
I don’t want to explain how to use the graph through complex Agents or other applications as a background. The graph can customize the Agent so that it is no longer a “black box.” In other words, LangGraph is a means to implement the Agent, but it does not mean that the Agent is LangGraph. There are other methods to implement the Agent, and the two cannot be equated.
Use case
If the user inputs “hello” to construct the sentence “hello,world!”, including punctuation. If the user does not input “hello”, then it’s an error.

A few concepts
LangGraph tells a story about a “graph”, which is basically a maze where each “loop” requires updating the overall “state” of the maze. It’s like there’s a big screen at the front of the maze that constantly updates the maze’s operational status.
You can think of the whole graph as a state machine, these two terms are interchangeable.
Termiknowledge
node: It’s just a function or method, you know.
- start-node: No doubt, it’s the first function to be called, it’s the one that starts the whole graph.
- condition: A function, it’s crucial to have a function to determine what to do next based on the start-node’s output. The inside of this function is checking the graph state after processing the start-node (if-else), and then it returns a string. This string will be mentioned in the conditional_edge_mapping described below, representing which node will be called after the start-node.
- conditional_edge_mapping: A dict that contains which nodes may be started next when the start-node activates the state machine. The keys of the dict are strings, which are one of the results returned by the condition. The values of the dict are the names of the nodes following the start-node. So everyone should understand this.
— — So: condition acts as a function to analyze the result of the start-node, determining which node will be considered next, and then returns a string, which will be associated with a node’s name through conditional_edge_mapping. - END. Pre-defined node by LangChain for the end of graph.
Some utility functions and classes
- Already mentioned, the graph has a state, so we need to define a class to store the state. This class can be anything, as long as it is a TypedDict (from typing import Dict, TypedDict):
class GraphState(TypedDict):
init_input: Optional[str] = None
first_word: Optional[str] = None
second_word: Optional[str] = None
final_result: Optional[str] = None - Instantiate graph
workflow = StateGraph(GraphState) - Every node needs a name, usually it can be the same as the function corresponding to the node, so that conditional_edge_mapping can identify which node will be mapped as a possible successor to the start-node:
def input_first(state: GraphState) -> Dict[str, str]
def input_second(state: GraphState) -> Dict[str, str]
def complete_word(state: GraphState) -> Dict[str, str]
workflow.add_node(“input_first”, input_first)
workflow.add_node(“input_second”, input_second)
workflow.add_node(“complete_word”, complete_word)
— Three functions, basically three nodes, each named. - Edge, actually just a route, indicating where to go after finishing one node, note that it does not include the start node because the condition, conditional_edge_mapping, determines the start-node`s follower.
workflow.add_edge(“input_second”, “complete_word”)
workflow.add_edge(“complete_word”, END)
— When the input_second node ends, complete_word will start, and when complete_word finishes, END is called. - workflow.set_entry_point(), no doubt, what needs to be specified is the start-node, just pass in the name of the node you want as the start-node, like “input_first”.
- workflow.add_conditional_edges(), when defining the start-node, it is necessary to specify the condition and conditional_edge_mapping. This function has three parameters:
- the name of the start-node
- a pointer to the condition function, which is the name of the function. The signature of this function is the state of the graph, and it returns an enumeration, as mentioned earlier, which is one of the keys in the conditional edge mapping.
- a dict, as you know above. - Run the graph, call compile and pass the argument to activate the start node, in dictionary format:
app = workflow.compile()
app.invoke({“init_input”: “hello”})
Use Case Implementation
We’re going back to the use case
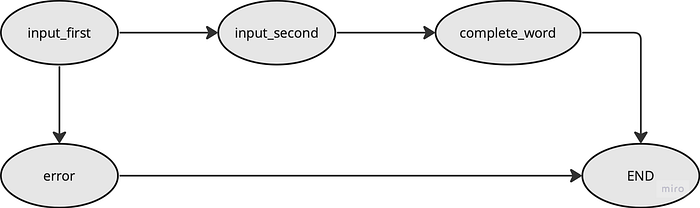
- Graph state
we’re defining the state of the graph in a simple way including:
Init_input: User’s input
First_word: The first word
Second_word: The second word
Final_result: The final result.
class GraphState(TypedDict):
init_input: Optional[str] = None
first_word: Optional[str] = None
second_word: Optional[str] = None
final_result: Optional[str] = None- Graph nodes
We define four nodes to each set one of the four fields in the graph’s state. This is pretty easy to remember, in my experience, each field pretty much corresponds to a node function.
def input_first(state: GraphState) -> Dict[str, str]:
print("""start input_first()""")
init_input = state.get("init_input", "").strip()
if init_input != "hello":
return {"first_word": "error"}
return {"first_word": "hello"}
def input_second(state: GraphState) -> Dict[str, str]:
print("""start input_second()""")
if state.get("first_word") == "error":
{"second_word": "error"}
return {"second_word": "world"}
def complete_word(state: GraphState) -> Dict[str, str]:
print("""start complete_word()""")
if state.get("first_word") == "error" or state.get("second_word") == "error":
return {"final_result": "error"}
return {"final_result": state["first_word"] + ", " + state["second_word"] + "!"}
def error(state: GraphState) -> Dict[str, str]:
print("""start error()""")
return {"final_result": "error", "first_word": "error", "second_word": "error"}- Continue function
When processing as the start node, it means deciding which direction the graph should go after the input_first. This is specified by “to_input_second” and “to_error” respectively. As mentioned earlier, all mappings will use these two strings to indicate which node will be the successor of the start node.
def continue_next(
state: GraphState,
) -> Literal["to_input_second", "to_error"]:
print(f"continue_next: state: {state}")
if state.get("first_word") == "hello" and state.get("second_word") == None:
print("- continue to_input_second")
return "to_input_second"
if (
state.get("first_word") == "error"
or state.get("second_word") == "error"
or state.get("final_result") == "error"
):
print("- continue to_error")
return "to_error" - Set up a graph with all the nodes named and the edges defined. It needs to be emphasized again that the so-called edge refers to the path that nodes other than the start node need to take, each specified by their respective node name. Additionally, the entry-point specifies the start-node.
workflow = StateGraph(GraphState)
workflow.add_node("input_first", input_first)
workflow.add_node("input_second", input_second)
workflow.add_node("complete_word", complete_word)
workflow.add_node("error", error)
workflow.set_entry_point("input_first")
workflow.add_edge("input_second", "complete_word")
workflow.add_edge("complete_word", END)
workflow.add_edge("error", END)- Keep going and map out the conditions of start-node. This is something very important for the start node, it indicates who the start node is, defines the mapping of the continue function and the successors of the start-node, Here are the possible nodes after the start node corresponding to to_input_second (continue function returns) and to_error.
workflow.add_conditional_edges(
"input_first",
continue_next,
{
"to_input_second": "input_second",
"to_error": "error",
},
)- Run graph
app = workflow.compile()
result = app.invoke({"init_input": "hello"})- Successfully output
See: input_first is called first, then continue function determines the to_input_second, so the input_second node is triggered as the conditional_edge_mapping defines, later because in the edge definition: workflow.add_edge(“input_second”, “complete_word”) so complete_word is triggered.
complete_word goes to END for the same reason.
start input_first()
continue_next: state: {'init_input': 'hello', 'first_word': 'hello', 'second_word': None, 'final_result': None}
- continue to_input_second
start input_second()
start complete_word()
Result:
{'init_input': 'hello', 'first_word': 'hello', 'second_word': 'world', 'final_result': 'hello, world!'}- Error output
See: input_first is called first, then continue function determines the to_error, because the input is not “hello”, so the error node is triggered as the conditional_edge_mapping defines, later because in the edge definition: workflow.add_edge(“error”, END) so the whole graph terminated at END.
result = app.invoke({"init_input": "hey"})
print("Result:")
print(result)
start input_first()
continue_next: state: {'init_input': 'hey', 'first_word': 'error', 'second_word': None, 'final_result': None}
- continue to_error
start error()
Result:
{'init_input': 'hey', 'first_word': 'error', 'second_word': 'error', 'final_result': 'error'}