LangChain / Llama-Index: RAG with Multi-Query Retrieval
Enhance query context with intermediate queries during RAG to improve information retrieval for the original query.
Query Expansion
Query expansion works by extending the original query with additional terms or phrases that are related or synonymous.
Multi-Query Retrieval is a type of query expansion.
Mechanisms
When I input a query request, we first use a large language model to generate a similar query. I will use a similar query to retrieve relevant documents (nodes in the llama-index). This retrieved information will be used to query the context of the original query.
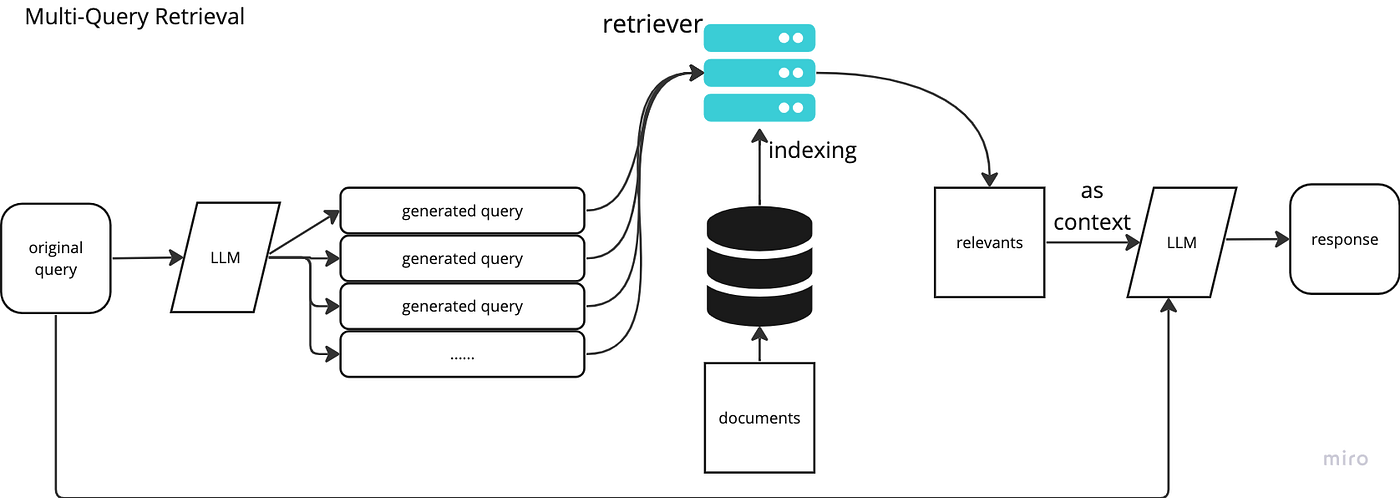
2 times LLM interactions
To generate queries, we need to make additional parallel requests to LLM. This means adding a total of 2 requests, with the option of using gpt3 as the first request and gpt4 or better for the final one.
Implementation method
LangChain
loader = UnstructuredPDFLoader(FILE_NAME)
docs = loader.load()
text_splitter = SentenceTransformersTokenTextSplitter()
texts = text_splitter.split_documents(docs)
emb = OpenAIEmbeddings(openai_api_key=openai.api_key)
vec_db = Chroma.from_documents(documents=texts, embedding=emb)
lc_model = ChatOpenAI(openai_api_key=openai.api_key, temperature=1.5)
base_retriever = vec_db.as_retriever(k=K)
final_retriever = MultiQueryRetriever.from_llm(base_retriever, lc_model)
tmpl = """
You are an assistant to answer a question from user with a context.
Context:
{context}
Question:
{question}
The response should be presented as a list of key points, after creating the title of the content,
formatted in HTML with appropriate markup for clarity and organization.
"""
prompt = ChatPromptTemplate.from_template(tmpl)
chain = {"question": RunnablePassthrough(), "context": final_retriever} \
| prompt \
| lc_model \
| StrOutputParser() \
result = chain.invoke("Waht is the doc talking about?")
MultiQueryRetriever provides ready-made classes to accomplish this task. The key point is to provide a base retriever. All “generated queries” will be automatically implemented, by default 3 of them. Their retrieval process will also be securely encapsulated.
As you can see in the colab, You will observe the intermediate generated queries such as:
INFO:langchain.retrievers.multi_query:Generated queries:
['1. What is the main topic discussed in the document?',
'2. Could you provide a brief summary of the subject matter of the document?',
'3. What does the document primarily cover and discuss?']Those queries will be used later to retrieve the relevant from the indices.
Llama-Index
The implementation of Llama-Index is quite tricky because we have to manually generate “generated queries” and their retrieval process is manually implemented. Since there are multiple queries, we will use the necessary coroutine mechanism.
vector_index: BaseIndex = VectorStoreIndex.from_documents(
docs,
service_context=service_context,
show_progress=True,
)
base_retriever = vector_index.as_retriever(similarity_top_k=K)
class MultiQueriesRetriever(BaseRetriever):
def __init__(self, base_retriever: BaseRetriever, model:OpenAI):
self.template = PromptTemplate("""You are an AI language model assistant. Your task is to generate Five
different versions of the given user question to retrieve relevant documents from a vector
database. By generating multiple perspectives on the user question, your goal is to help
the user overcome some of the limitations of the distance-based similarity search.
Provide these alternative questions seperated by newlines.
Original question: {question}""")
self._retrievers = [base_retriever]
self.base_retriever = base_retriever
self.model = model
def gen_queries(self, query) -> List[str]:
gen_queries_model = OpenAI(model="gpt-3-turbo", temperature=1.5)
prompt = self.template.format(question=query)
res = self.model.complete(prompt)
return res.text.split("\n")
async def run_gen_queries(self,generated_queries: List[str]) -> List[NodeWithScore]:
tasks = list(map(lambda q: self.base_retriever.aretrieve(q), generated_queries))
res = await tqdm.gather(*tasks)
return res[0]
def _retrieve(self, query_bundle: QueryBundle) -> List[NodeWithScore]:
return list()
async def _aretrieve(self, query_bundle: QueryBundle) -> List[NodeWithScore]:
query = query_bundle.query_str
generated_queries = self.gen_queries(query)
query_res = await self.run_gen_queries(generated_queries)
return query_res
mr = MultiQueriesRetriever(base_retriever, li_model)
final_res = await RetrieverQueryEngine(mr).aquery(query_text)The key point is that we inherit BaseRetriever, which means we combine it with a base retriever to query relevant information based on generated queries. _aretrieve must be overridden because generated queries are implemented through coroutine. No further details are explained here.
Furthermore, you have the opportunity to view the queries that were generated at an intermediate stage, if you print.
SubQuestionQueryEngine
Llama-Index provides a class called SubQuestionQueryEngine that basically meets our needs, the difference is, it’s break-down, not generate a “similar” query. According to the documentation, you can use the following code:
query_engine_tools = [
QueryEngineTool(
query_engine=vector_query_engine,
metadata=ToolMetadata(
name="pg_essay",
description="Paul Graham essay on What I Worked On",
),
),
]
query_engine = SubQuestionQueryEngine.from_defaults(
query_engine_tools=query_engine_tools,
use_async=True,
)
response = query_engine.query(
"How was Paul Grahams life different before, during, and after YC?"
)The SubQuestionQueryEngine works by breaking down the original query into sub-questions, each of which is directed to a relevant data source. The intermediate answers from these sub-questions are used to provide context and contribute to the overall answer. Each sub-question is designed to extract a specific piece of information from the data source it is directed to. The responses to these sub-questions are then combined to form a comprehensive answer to the original query.
On the other hand, the SubQuestionQueryEngine breaks down a complex query into many sub-questions and their target query engine for execution. After executing all sub-questions, all responses are gathered and sent to a response synthesizer to produce the final response. The SubQuestionQueryEngine decides which QueryEngineTool to use for each sub-question based on the tool_name attribute of the SubQuestion object.
