Experimentation: LLM, LangChain Agent, Computer Vision
Consider utilizing the Large Language Model(LLM) for automating annotation tasks, or for performing automatic object detection in Computer Vision, using the Agent (function in OpenAI) within LangChain.

In other words, what we’re doing here is object detection without any human intervention. All we do is upload an image, then use an Agent mechanism to automatically locate the relevant features using LLM. This function is referred to as “function” in OpenAI, and “tool” in LangChain. But for convenience, we’ll stick with calling it “function” here.
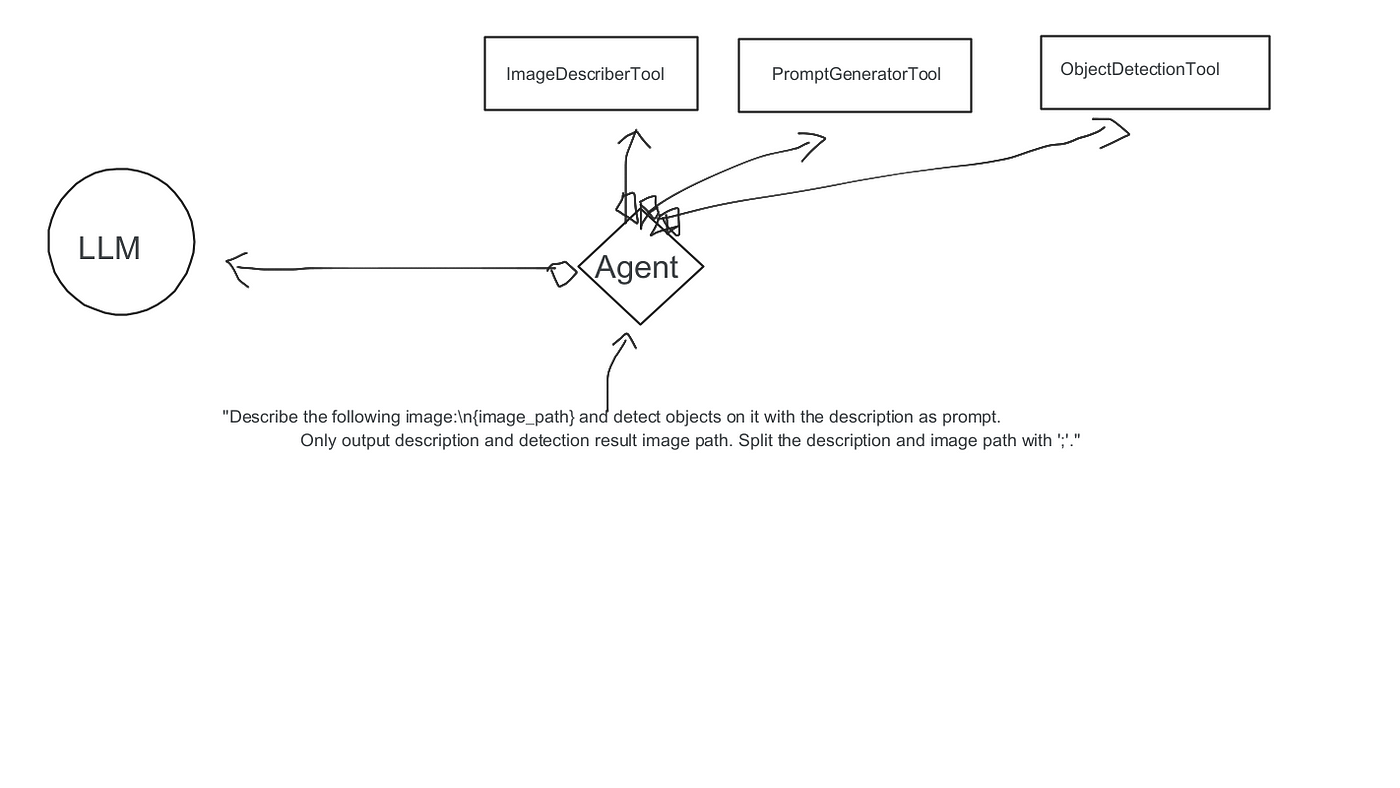
Basically, we have an application that works like this: we input a prompt, for instance, we want the application to understand an image, extract some information it describes, and provide descriptions and annotations of described objects. Finally, it returns to us the image description and the annotated image path.
Agent, LLM
I’m going to discuss this all at once, because in LangChain, when we initialize the Agent, we need to input an LLM.
from langchain.agents import initialize_agent
initialize_agent(
agent=AgentType.STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION,
tools=[
ImageDescriberTool(),
ObjectDetectionTool().setup(
groundingDINO_model=groundingDINO_model
),
PromptGeneratorTool().setup(llm),
],
llm=llm,
verbose=True,
max_iterations=3,
early_stopping_method="generate",
memory=ConversationBufferMemory(
memory_key="chat_history",
return_messages=True,
),
)When initializing the Agent, you need to provide the “tool” that this Agent will “schedule”, and once again, for convenience, we still call it “function” (same goes below). The following text will mention the 3 functions referred to here, which we won’t elaborate on atm. Importantly, the Agent may need a history memory, which is very useful in the given “chat” application, so that the LLM can always follow the user’s interaction experience with the AI. However, this is not the focus of this article.
Function(s)
Our app mainly performs the following functions:
- Upload an image and accept a prompt based on the above requirement description.
- Describe the image to get description information.
- Extract the necessary “internal prompts” using image description information (note, this is not the prompt when we ask the App).
- Use the object detection model based on semantic cues, which is very common in computer vision, to detect objects. Complete the “annotations” based on the results of the object detection model and return the path of the annotated image.
- Provide the final answer: Description of the picture; Path to the annotated image.
Function-list
ImageDescriberTool
To describe images, we use one of the following two models here, which will consume an image and return a string describing the image.
Salesforce/blip-image-captioning-base · Hugging Face
Salesforce/blip-image-captioning-large · Hugging Face
You can use this Colab to familiarize yourself with their uses. I won’t dwell on the pros & cons here as it’s not the focus.
PromptGeneratorTool
This function is designed to simplify the internal prompt we give to the object detection model. For the object detection model, prompts consisting mainly of simple words can enhance efficiency. Here’s an example:
Image Description:
“a little girl sitting on the floor next to a christmas tree”
We got it through a call to LLM:
“girl, floor, christmas tree”
Regarding how to get information about it on LLM, we can prompt as follows:
"""Remove the stop words and useless words, only keep the 'objects', from the following sentence:
{image_desc}
List the objects, separating each with a comma. """ObjectDetectionTool
This function is actually a core business, which is object detection. We use GroundingDINO, and won’t go into detail about its features here. The main method of using it is to give the model a caption(phrase, prompt, whatever….), like “girl, floor, Christmas tree.” Then, the model can detect the targets it understands. We are based on a pretrained model, so performance is limited, but it’s sufficient to illustrate the problem.
Function Declaration
All functions must be accurately defined, we must provide a name and a description. Under the LangChain framework, we need to do something similar to:
class ObjectDetectionTool(BaseTool):
name = "Object detection on image tool"
description = "Use this tool to perform an object detection model on an image (read an image path) to detect object with a text prompt"
def _run(self, image_path: str, prompt: str) -> str:
....
def _arun(self, query: str):
raise NotImplementedErrorScheduling of functions
We already have the Agent, LLM, and Functions. Now let’s talk about the “possible” scheduling. I say “possible” because the entire scheduling process is carried out by the LLM, or AI. Thus, the “Function Declaration” is extremely important, it needs to be as precise as possible so that the AI knows what each function does.
Here’s a basic layout:

Firstly, for the input images and prompt, the action initiated first by the Agent is for ImageDescriberTool:
“action”: “Describe image tool”
It’s not hard to understand here, our prompt’s first word is “Describe”, and the definition of function is quite clear:
class ImageDescriberTool(BaseTool):
name = "Describe image tool"
description = "Use this tool to describe found objects an image"After consumption by the ImageDescriberTool, the model will remember the image description information provided by this function. Subsequently, the next action will be invoked by the Agent for the PromptGeneratorTool.
“action”: “Image object detection prompt generator tool”
class PromptGeneratorTool(BaseTool):
name = "Image object detection prompt generator tool"
description = "Use this tool to generate prompt based on the description of the image for object detection model"This function “might” be triggered for the reason that it’s “based on the description of the image”. Please note that here I’m also saying “might”.
After getting the internal prompt of the object detection model, plus the image path known from the previously uploaded image, the Agent will naturally coordinate with the ObjectDetectionTool:
“action”: “Object detection on image tool”
This can be understood from the declaration of the function:
class ObjectDetectionTool(BaseTool):
name = "Object detection on image tool"
description = "Use this tool to perform an object detection model on an image (read an image path) to detect object with a text prompt"Make some explanations here
The entire scheduling is autonomously managed by AI, with each function’s description playing a pivotal role. If the description is not strong, the PromptGeneratorTool might be overlooked, and the results from the ImageDescriberTool would be applied to the ObjectDetectionTool. Overall, there won’t be any major issues, as the ObjectDetectionTool is essentially based on any possible phrase.
Final Action
The scheduling of the last Action, which is what is called:
“action”: “Final Answer”
This is built-in, it will again combine the external input to the app’s prompt and the “path of the annotated image” provided by the ObjectDetectionTool (Observation) to provide the final result, the last AIMessage:
“a little girl sitting on the floor next to a christmas tree;output/2023–11–15–10–01–50.png”
Pay attention to the semicolon at the top, this is because we have the following in the prompt:
List the objects, separating each with a comma.Full code check
Started by
streamlit run advanced/image_auto_annotation.py — server.port 8006 — server.enableCORS false
For the first-time run, the pretrained models will need to be downloaded and this can cause a delay needing patience, waiting and waiting. Once downloaded, you can refresh the page.
Salesforce/blip-image-captioning-base · Hugging Face
Salesforce/blip-image-captioning-large · Hugging Face
Big Question
Upon seeing this, people may ask, why we need to use an Agent. From the perspective of app design, it seems we don’t need any AI or so-called scheduling, especially when one of the functions is not 100% called (PromptGeneratorTool). We could easily follow traditional programming methods, first invoke the ImageDescriberTool, then the PromptGeneratorTool, and finally the ObjectDetectionTool, to get the same result. Isn’t this the right approach?
Absolutely no problem, you can do it this way. In fact, I would also choose to do so. As the first possible approach, I would use this method to validate each function. Manual intervention is completely reliable, isn’t it?
Then, when dozens of functions may be used by the app, AI scheduling becomes another option. What we need to do is provide each function with a necessary and useful description; the more precise, the more reliable.
Pros
Did you notice? These functions do not have an “active, explicit” utility in this app. The whole process begins with an external prompt providing enough input and output information. This one sentence replaces what could potentially be dozens of function calls.
Cons
As the number of functions increases and the consumption of functions themselves needs to be executed, the time of the entire scheduling process also increases, especially when using a remote deployed model like OpenAI’s LLM. It is recommended to deploy LLM to the local environment using https://ollama.ai/.
Final
That’s it, use AI to select the suitable functions, learn more English, improve English writing ability, and enhance the quality and level of function description.
This is the software development process in the AI era based on different models.