Chat with your PDF (Streamlit Demo)
Utilize the flow of the chatting with your own documents to interact with my PDF.

Recently, many people have been discussing the use of LLMs, which can be basically divided into:
- Fine-tuning (Training pretrained model, Transfer learning, etc.)
- Applications based on LLMs, especially the very popular LangChain.
This time, I will provide a relatively advanced model of LangChain to communicate with a certain PDF file. I have shared the complete code here. If you want to understand the code, just go there directly. The process is explained based on Streamlit, as shown below:


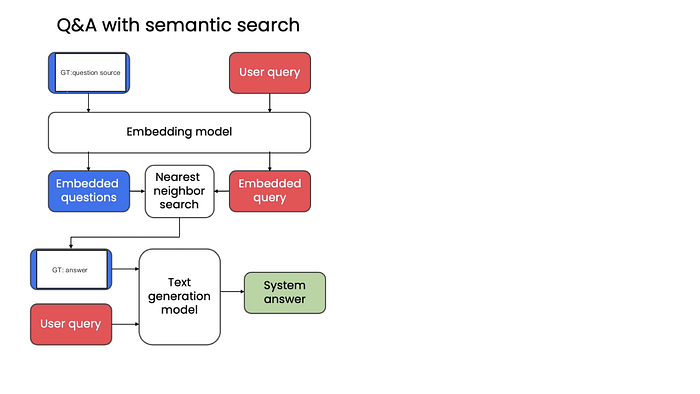
Flow
1st approach(Chroma)
- Read the PDF file (in fact, any file type can be read).
- Divide the content of each file into several documents.
- Embed each document using OpenAI’s API (other API is also possible).
- Establish a vector storage(Chroma) for these embeddings.
- When posing a question, identify the most pertinent documents and forward them as context to GPT to solicit a well-constructed response.
- When responding, supply the source documents utilized and the corresponding answer.


2nd approach(FAISS)
- Read the PDF file (in fact, any file type can be read).
- Divide the content of each file into several documents.
- Embed each document using OpenAI’s API (other API is also possible).
- Establish a vector storage(FAISS) for these embeddings.
- Utilize VectorDBQAWithSourcesChain to pinpoint documents in the DB comparable to the LLM query, grounded on the presented question, and continue directly to extract the relevant answer using LLM. The LLM operation is performed twice.



Code snippet
1st approach(Chroma)
from langchain.embeddings import OpenAIEmbeddings
from langchain.llms import OpenAI
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Chroma def load_and_split(path: str, is_unstructured: bool = True):
logger.info(f"Loading {path}, Unstructured: {is_unstructured}")
loader = UnstructuredPDFLoader(path) if is_unstructured else PyPDFLoader(path)
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(docs)
return texts
llm = OpenAI(temperature=0.5)
qa_chain = load_qa_chain(llm, chain_type="stuff")
vectordb = Chroma.from_texts(
texts=[c.page_content for c in pdf_content],
embedding=embeddings,
persist_directory=persist_directory,
)
vectordb.persist()
#
# Retrieve the most similar documents.
# For max_marginal_relevance_search, the documents are far-apart from each other.
#
m = (
vectordb.similarity_search
if sim_method == sim_methods[0]
else vectordb.max_marginal_relevance_search
)
q_rs = m(
question,
k=num_docs,
fetch_k=6,
lambda_mult=1,
)
question = f"{question}(answer from {src_lang} to {dist_lang}, optimising is {optimising}"
answer = qa_chain.run(input_documents=q_rs, question=question)2nd approach(FAISS)
from langchain.chains import VectorDBQAWithSourcesChain
from langchain.chat_models import ChatOpenAI
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS llm = ChatOpenAI(model="gpt-4-0613")
embeddings = OpenAIEmbeddings()
faiss_store = FAISS.from_texts(
[txt], self._embeddings, metadatas=[{"source": url}]
)
faiss_store = FAISS.from_texts(
[txt], self._embeddings, metadatas=[{"source": url}]
)
with open("db/faiss_store.pkl", "wb") as f:
pickle.dump(faiss_store, f)
with open("db/faiss_store.pkl", "rb") as f:
faiss_store = pickle.load(f)
#
# AI -> find out similar docs
# AI -> answer question
#
chain = VectorDBQAWithSourcesChain.from_llm(
llm=self._llm,
vectorstore=faiss_store,
)
q = st.text_input("What is ...?")
res = chain({"question": self.prompt.format(txt=q)})Complete Code
1st approach(Chroma)
2nd approach(FAISS)
Avoid judging these methodologies as good or bad; their suitability simply depends on the type of project you are involved in.
Apart from hand-drawn pictures and APP screenshots, all other text and images are referenced from the following training courses:
Additional resource
To begin exploring semantic search without LangChain, start the course here. It is quite beneficial in gaining an intuitive understanding of how LangChain operates behind the scenes. Sometimes that one example is enough to get the vision.