LangChain/LangGraph: Build Reflection Enabled Agentic
In this article, we create an AI Agent that has what is called reflection. We rely solely on LangChain to simplify model calls and only use Ollama to reduce the cost of model calls. Finally, we use this Agent to make a predictive report on the best time to purchase a MacBook.
Notice: The content and code of this experiment are limited to explaining the operation principles of the Agent, suitable for teaching and learning, and personal side projects. It is not recommended to directly apply it in actual production environments.

Agent concept
We can understand an Agent as one that continuously calls different Tools through AI, ultimately allowing the AI to respond or reach the desired outcome of the user. The Tool can be an API, a set of remote or local APIs, another Agent, or a call to an AI model.

Early implementation of Agents (About 2022–2024)
This is actually a personal opinion of mine. As the application of Graph has become widespread, the implementation of Agents has indeed changed. The initial implementation method (ref. LangChain) was indeed a while(true) running in the background. This loop is used to consume possible Tools based on the AI’s responses after the user asks questions.
Note that we are not discussing a chat session; we are talking about a user asking a question once and then waiting for the AI’s response.

I once wrote two articles introducing this implementation method, using LangChain and LlamaIndex respectively.
Currently popular implmentation
With various frameworks launching their own Graph components, the creation of agents is now gradually shifting towards them. These components aim to establish AI-based workflows, or what can be termed as agentic flow. Here are a few examples:
LangChain, LangGraph:
https://python.langchain.com/docs/concepts/architecture/#langgraphLlamaIndex, Workflows:
https://docs.llamaindex.ai/en/stable/module_guides/workflow/#workflowsCrewAI, Flows:
https://docs.crewai.com/concepts/flowsPydanticAI, Graphs:
https://ai.pydantic.dev/graph/#graphs
Their work goals are similar; LangGraph and PydanticAI Graphs are close, while LlamaIndex Workflows and CrewAI Flows are very similar, leaning more towards an event-driven feel, and LangGraph has almost become the industry favorite.
I indeed used LlamaIndex Workflows to create two case studies on agentic reflection translation. For the origin of this case, you can refer to here:
Our Work
- Implement Agent using Graph (LangGraph)
- The Agent has self-reflection capabilities, just like agenic translation.
- Two chains are used, one for QA, one for reflection.
- Switching between the nodes can resolve the loop logic.
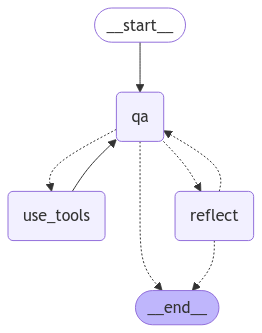
Introduction
There are three nodes(graph functions) :
qa: AI model, used for question and answer; qa can terminate the entire graph (state[“curr_iter”] > MAX_ITERATIONS — 1), we define MAX_ITERATIONS to control and avoid endless back-and-forth between qa and reflect.
use_tools:Call the Tools for AI prompts.
reflect: Reflecting on the results of each QA, it can terminate the entire graph (abort), because the QA has provided extremely satisfactory results, making it unnecessary for the AI to re-QA.
Notice: Reflection applies ONLY on the QA interaction, which means the Tool results won’t be evaluated by it.
Implementation
The code section uses Ollama entirely. The basic configuration uses Llama 3.1 for searching and chat and DeepSeek R1 14b for reflection. Here, I suggest using a GPU, either with MacOS or finding a GCP Cloud Run. But none of this is particularly important.
The running speed depends on the hardware; in my case, I have a small GPU which takes several minutes, and after one attempt, I must wait until the memory is freed.
Full code
https://github.com/XinyueZ/chat-your-doc/blob/master/advanced/lg_ollama_hands_on_reflection_agent.py
reflection-chain
Here I would like to make a point: the prompt of this chain includes a check for “hallucinations,” which is very important. Through multiple experiments, it has been found that although the results often revolve around the topic of “MacBook Pro price inquiries,” occasionally, well, there are multiple occurrences of “discussing the stock price of Apple Inc,” which is the most typical example of a “hallucination.”
Full reflection, check here.
k. Check for hallucination: Determine if the AI's response contains information beyond the scope of the user's question. If so, highlight these instances by quoting the relevant parts and explaining why they might be considered hallucination.
....
7. Hallucination Check:
[Report on any instances of the AI providing information beyond the scope of the user's question]Critic as HumanMessage (user message)
This is a technical question. Although this experiment only supports one question at a time, we will find that after the reflection chain, we want the model to improve the quality of its responses to the question. This user message is NOT a new question or external input, so to differentiate it, this message will be accompanied by the information “internal: critic”. The following is the approach taken in LangChain:
"messages": [
HumanMessage(content=critic_message, additional_kwargs={"internal": "critic"})
],When I want to extract the user’s most recent meaningful question or input, the internal field must not be empty.
user_question = intermediate_steps = [
msg
for msg in whole_conversation
if isinstance(msg, HumanMessage)
and msg.additional_kwargs.get("internal", None) is None
][-1] # Ensure the last HumanMessage is a question not a critic.Alright, these are just some tips that aren’t too related to the Agent.
Full critic prompt, check here.
Reflection via DeepSeek R1 14B
This version of the model does not support tools (Ollama), which means that structured output is very problematic. Although there are workaround methods to address this, it cannot be said that it is not possible. Here is an article for reference:
However, I still used the early method for processing structured outputs in LangChain:
reflection_structured_output_parser = StructuredOutputParser.from_response_schemas(
[
ResponseSchema(
name="Has Reflection",
description="'yes' if reflection is required, 'no' otherwise",
type="string",
),
ResponseSchema(
name="Overall Assessment",
description="Provide a concise summary of the AI's performance",
type="string",
),
ResponseSchema(
name="Detailed Analysis",
description="""1. Content:
[Evaluate the accuracy and completeness of the information provided]
2. Tone:
[Assess the appropriateness of the AI's tone and language]
3. Structure:
[Comment on the organization and flow of the response]
4. Strengths:
[Highlight what the AI did well]
5. Areas for Improvement:
[Identify specific aspects that need enhancement]
6. Tool Usage:
[If applicable, evaluate the effectiveness of tool calls]
7. Hallucination Check:
[Report on any instances of the AI providing information beyond the scope of the user's question]
""",
type="List[string]",
),
ResponseSchema(
name="Conclusion and Recommendations",
description="Summarize key observations and provide actionable suggestions for improvement",
type="string",
),
]
) reflection = reflection_chain.invoke(
input={
"USER_QUESTION": user_question.content,
"LAST_AI_RESPONSE": last_ai_response_content,
"FORMAT_INSTRUCTIONS": reflection_structured_output_parser.get_format_instructions(),
}
)def get_reflection_content(reflection: str) -> str:
logger.info(reflection)
if (
"Has Reflection" not in reflection
or """
"Has Reflection": "no"
""".strip()
in reflection
):
return ""
return reflectionThis processing method ensures that R1 guarantees a fixed JSON format output to a certain extent at some degrees:
```json
{
"Has Reflection": "yes",
"Overall Assessment": "The AI's response effectively addresses the user's query with relevant data and insights but has areas for improvement in specificity, source citations, and structural adherence.",
"Detailed Analysis": [
"Evaluation of accuracy: The AI provided historical price trends and made reasonable predictions but included speculative elements like '€2500-3000' without explicit sources for 2025.",
"Tone assessment: Appropriate and informative, though could be more tailored to the user's specific location (Germany) with price examples in Euros.",
"Structural evaluation: The response had a logical flow but didn't strictly follow the numbered sections as requested.",
"Strengths: Use of reputable sources and clear explanation of purchase timing.",
"Areas for improvement: More precise source citations for price figures, explicit connection to Germany's market trends, and adherence to the specified structure.",
"Tool Usage: Effectively used sources like Apple's site and macpricehistory.com, but could include direct links or more detailed references.",
"Hallucination check: No major instances identified, but speculative price ranges needed clearer justification."
],
"Conclusion and Recommendations": "The AI provided a solid foundation with accurate historical data. Future improvements should focus on clearer source citations for pricing, explicit application of the user's structural format, and more detailed justifications for price predictions to avoid potential hallucination concerns."
}
```I certainly hope to use with_structured_output and bind_tools, but things didn’t go as planned; I’d suggest referring to this article for more details.
In fact, when reflecting on the role of the chain, the key is not whether the output is in JSON format, but whether the content has a reliable fixed format output. As long as it can be converted to a string, that’s sufficient.
At the same time, “Has Reflection” can be judged.
Full reflection prompt, check here.
Environment
Take care of those environment variables for your attempt:
ollama_host = os.getenv("OLLAMA_HOST")
os.environ["SERPER_API_KEY"] = os.getenv("SERPER_API_KEY")
os.environ["JINA_API_KEY"] = os.getenv("JINA_API_KEY")
os.environ["BRAVE_SEARCH_API_KEY"] = os.getenv("BRAVE_SEARCH_API_KEY")
os.environ["LLM_TEMPERATURE"] = os.getenv("LLM_TEMPERATURE", 1.0)
os.environ["LLM_TOP_P"] = os.getenv("LLM_TOP_P", 1.0)
os.environ["LLM_TOP_K"] = os.getenv("LLM_TOP_K", 30)
os.environ["LLM_TIMEOUT"] = os.getenv("LLM_TIMEOUT", 120)The tool list, DuckDuckGoSearchRun is at least required to support internet search, the rest can be optional.
@tool(
"get_current_datetime",
return_direct=True,
parse_docstring=True,
)
def get_current_datetime() -> str:
"""Get the current datetime."""
current_time = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
logger.info(f"🧭 Retrieved current time: {current_time}")
return current_time
class TranslateSchema(BaseModel):
"""Translate the given text from the given language to the given language."""
text: str = Field(description="The text to translate.")
from_lang: str = Field(description="The language to translate from.")
to_lang: str = Field(description="The language to translate to.")
@tool(
"translate",
return_direct=True,
args_schema=TranslateSchema,
parse_docstring=True,
)
def translate(text: str, from_lang: str, to_lang: str) -> str:
"""Translate the given text from the given language to the given language."""
return translate_model.invoke(
[
(
"system",
f"""You are a helpful translator. Translate the user sentence from {from_lang} to {to_lang}. The origin text is in <user_text></user_text>.
Return the result without any extra information including instructions or any tags or marks.""",
),
("human", f"<user_text>{text}</user_text>"),
]
).content
class OpenUrlSchema(BaseModel):
"""Input, for opening and reading a website."""
website_url: str = Field(..., description="Mandatory website url to read")
@tool(
"open_url",
return_direct=True,
args_schema=OpenUrlSchema,
parse_docstring=True,
)
def open_url(website_url: str) -> str:
"""A tool that can be used to read the content behind a URL of a website."""
return requests.get(
f"https://r.jina.ai/{website_url}",
headers={
"Authorization": f"Bearer {os.environ['JINA_API_KEY']}",
"X-Return-Format": "markdown",
"X-Timeout": "120",
},
timeout=60,
).text
web_search_description = (
"a web-search engine. "
"useful for when you need to answer questions about current events."
" input should be a search query."
)
tools = [
get_current_datetime,
translate,
open_url,
YahooFinanceNewsTool(),
Tool(
name="Web search (Google) on the Internet",
func=GoogleSerperAPIWrapper(k=13).run,
description=web_search_description,
),
WikidataQueryRun(api_wrapper=WikidataAPIWrapper()),
WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper()),
DuckDuckGoSearchRun(description=web_search_description),
BraveSearch.from_api_key(
api_key=os.getenv("BRAVE_SEARCH_API_KEY"),
search_kwargs={"count": 10},
description=web_search_description,
),
]
tools_by_names = {tool.name: tool for tool in tools}
qa_model_with_tools = qa_model.bind_tools(tools)Result
The result of the report is an output similar to markdown, but I took the lazy way out and used the Console class to output directly. You can use a real file output for markdown, and the result will have a similar effect.
0. Explain our goals, which is also the main purpose of this report
Optimal Purchase Time for MacBook Pro Max in 2025
Based on our thorough analysis, we've put together this report to help you find the best time to buy a MacBook Pro Max in 2025.
Price Trends Over Three Years (2022-2024)
Using reliable sources like Apple's official website and WikiData, we analyzed the historical price trends for the MacBook Pro Max over the past three years:
Year Price Range (Euro) Location
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
2022 €1,799 - €2,299 Germany
2023 €1,899 - €2,399 Europe
2024 €1,999 - €2,499 Worldwide
Note: Prices may vary depending on your location and retailer.
Expected Price for 2025
Based on historical trends and annual price increases:
Expected Price Range (Euro) in 2025
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
Min. Configuration: €2,199 - €2,499
Mid-Range: €2,499 - €3,099
High-End Model: €3,399 - €4,299
Seasonal Promotions and Optimal Purchase Time
To secure the best deals, consider buying during:
1 Apple's Back-to-School Promotion: Typically starts in July each year, offering discounts on MacBooks for students and educators.
2 Black Friday: Occurs in November, with many retailers offering significant discounts on MacBooks.
3 Holiday Season (December): Some retailers offer exclusive deals during this period.
Why These Times are Advantageous
1 Increased demand during peak seasons typically drives retailers to offer discounts.
2 Many promotions are specific to students or educators, which might be relevant to your needs.
3 Taking advantage of sales timing can save you money on the MacBook Pro Max.
Additional Recommendations
1 Keep an eye on price fluctuations and retailer promotions throughout the year.
2 Consider waiting for new models, but ensure compatibility with existing apps and services.
3 If possible, purchase during off-peak seasons to maximize savings.
Conclusion
To find the optimal purchase time for a MacBook Pro Max in 2025, we recommend analyzing these historical trends, keeping an eye on seasonal promotions, and possibly waiting for new models to be released. Remember to convert prices accurately to Euros from your location and factor in any additional costs associated with purchasing in 2025.
Recommendations: Consider consulting Apple's official website or reputable retailers like Amazon or Best Buy for the latest deals and promotions.References
•Agents https://ppc.land/content/files/2025/01/Newwhitepaper_Agents2.pdf
•Building Effective Agents https://www.anthropic.com/research/building-effective-agents
•AGENTIC RETRIEVAL-AUGMENTED GENERATION: A SURVEY ON AGENTIC RAG
